
By Sondos Atwi @Sondos_4
On the 17th and 18th of November, I attended the Big Data Spain conference. It was my first time attending this type of events, and it was an excellent opportunity to meet experts in the fields and attend high-quality talks. So I decided to write this post to share a few of the presented slides and ideas.
Ps: Please excuse the quality of some slides/pictures, they were all taken by my phone camera!
First, Congrats to Big Data Spain on being the second biggest Big Data conference in Europe, right after O’Reilly Strata. This year’s edition also
had around 50% increase than last year’s!
Now let’s dig into the details…
Has AI Arrived? (A keynote by Paco Nathan, O’Reilly)
Machine Learning is further becoming a powerful tool for companies. It is helping them to better understand their customers, and helping us as individuals to easily find what we need.
If we think about successful tech start-ups, can we find one that is not actually applying some kind of machine learning? From this simple question we can sense how essential machine learning has become in shaping any company’s roadmap.

That said, there is still fear that AI will be coming for our jobs, which is understandable in the wake of self-driving cars, self-driving trucks, bots, etc. However, machine learning, or the ‘universal learner’, as Pedro Domingos describes it, is already part of our daily lives. It is growing at a very fast pace and touching every single industry, so staying ‘out’ of it is no longer an option, especially that it has also become easily accessible to non-experts. But we need to be aware that it can have a dark side when it’s not properly used.

In the end, it is essential to differentiate between machine and human capabilities. Machines are much better in some aspects (speed, scale, repeatability, etc.), whereas humans are better in others. And ultimately, knowing how to integrate both expertise will be key to success for any organization.

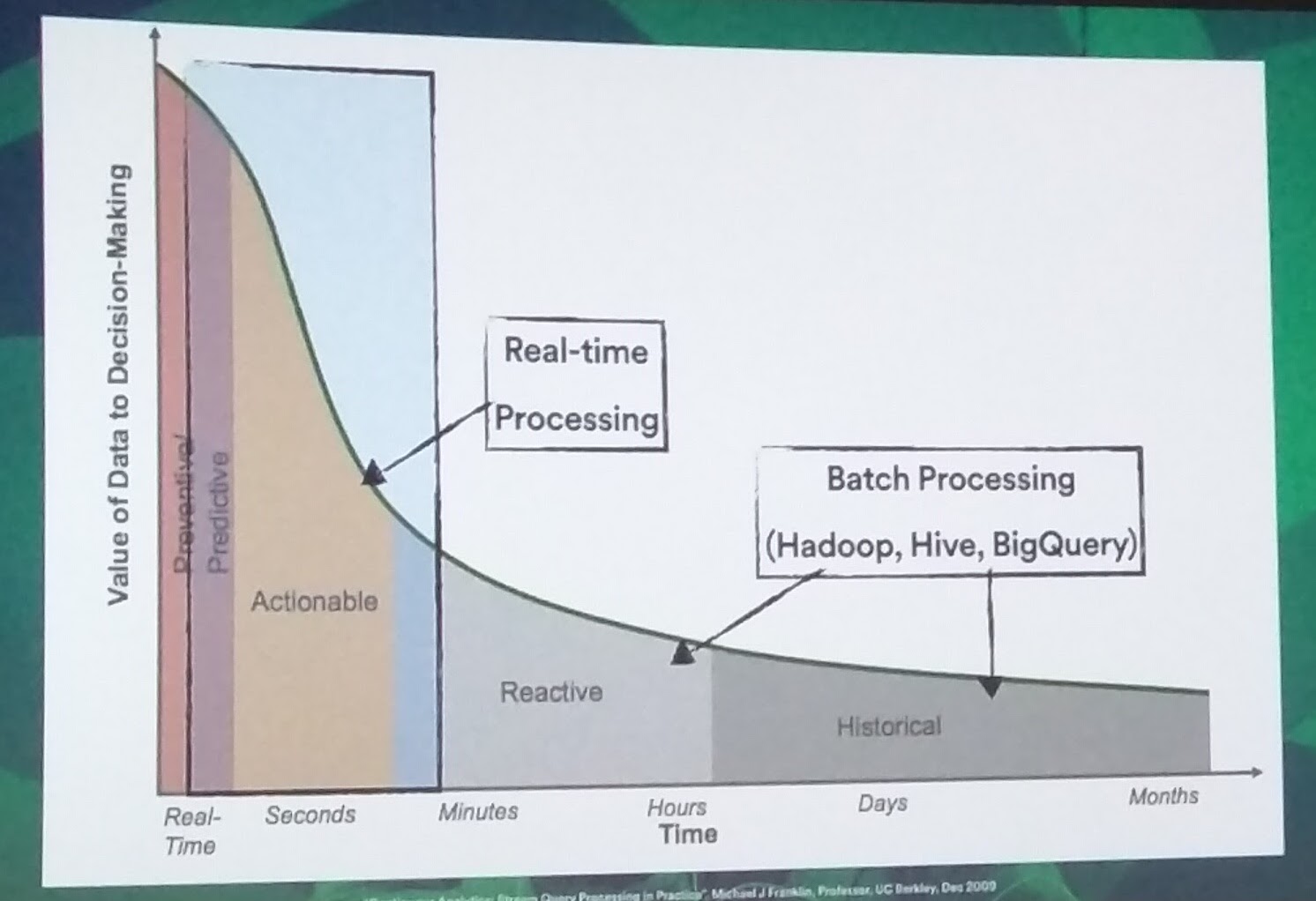
Shortening the feedback loop: How Spotify’s big data ecosystem has evolved to produce real-time processing (Josh Baer, Spotify)
As opposed to historical data and batch processing, which usually takes hours or days to clean and derive insights from, real-time processing provides instant insights and actionable data that allows us to take time-critical decisions.
When it comes to decision making, data is most valued when processed in real-time because it leads to a fast feedback loop. This, in turn, allows the early detection of bugs introduced by new features and can give developers real-time access to the data logged by the users.
Prepping Your Analytics Organization For Artificial Intelligence (Ramkumar Ravichandran, Visa)
Where do we stand with respect to AI?
It is important to keep in mind that AI may not be able to solve every problem. Now, as these systems continue to evolve, will AI intelligence ever reach Einstein’s intelligence, who we consider as a ‘superhuman’? If it does, will we ever be able to program common sense or creativity into a system?

On the other hand, organizations cannot start working on AI if they do not have the needed data and a mature analytics approach (which goes all the way to prescriptive analytics). These two are in fact are the foundations for AI. The data needs to be reliable and the machine should not be overwhelmed with unnecessary or noisy data for later processing.
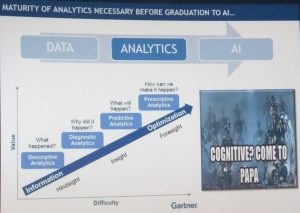
In addition, we should not think of AI as being a unique entity with only one role. It can rather be classified by capability. So while some AI systems are able to only execute one specific task, others can be much more complex, or may even be considered as super intelligent.

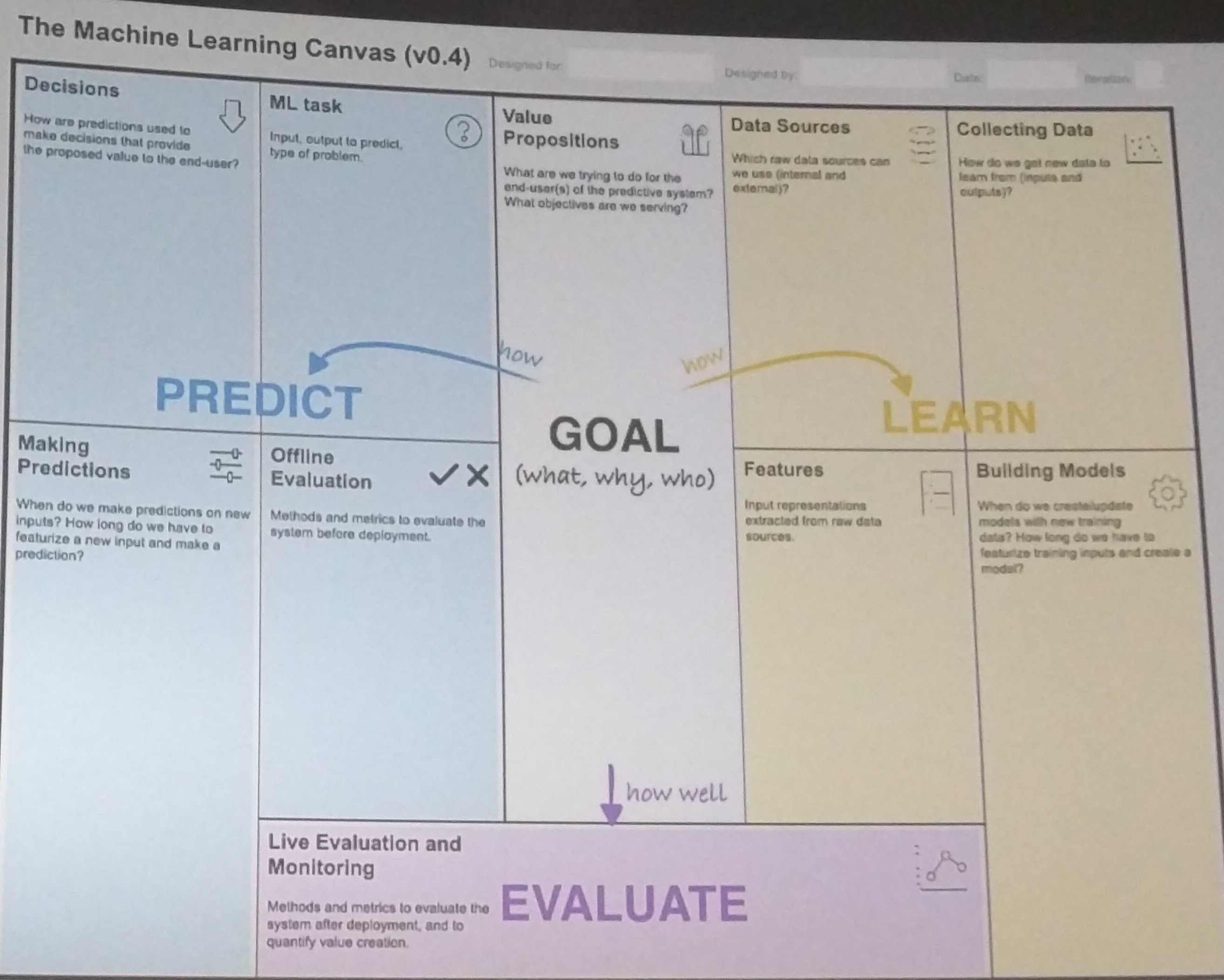
From Data to AI With The Machine Learning Canvas (Louis Dorard, PAPIs.io)
Louis presented the Machine Learning canvas, which is a template that can help organize and identify the tasks needed to develop predictive systems based on machine learning. By dividing the tasks into four categories (Goal, Predict, Learn, and Evaluate), it provides an explicit and systematic approach to tackling this type of projects.
Keynote by Chema Alonso, Telefónica
In this talk, Chema specifically focused on the topic “Location data collection.”
It is no secret that our smartphone is constantly tracking our location, even when our location services are off. So, how is our location data usually collected?
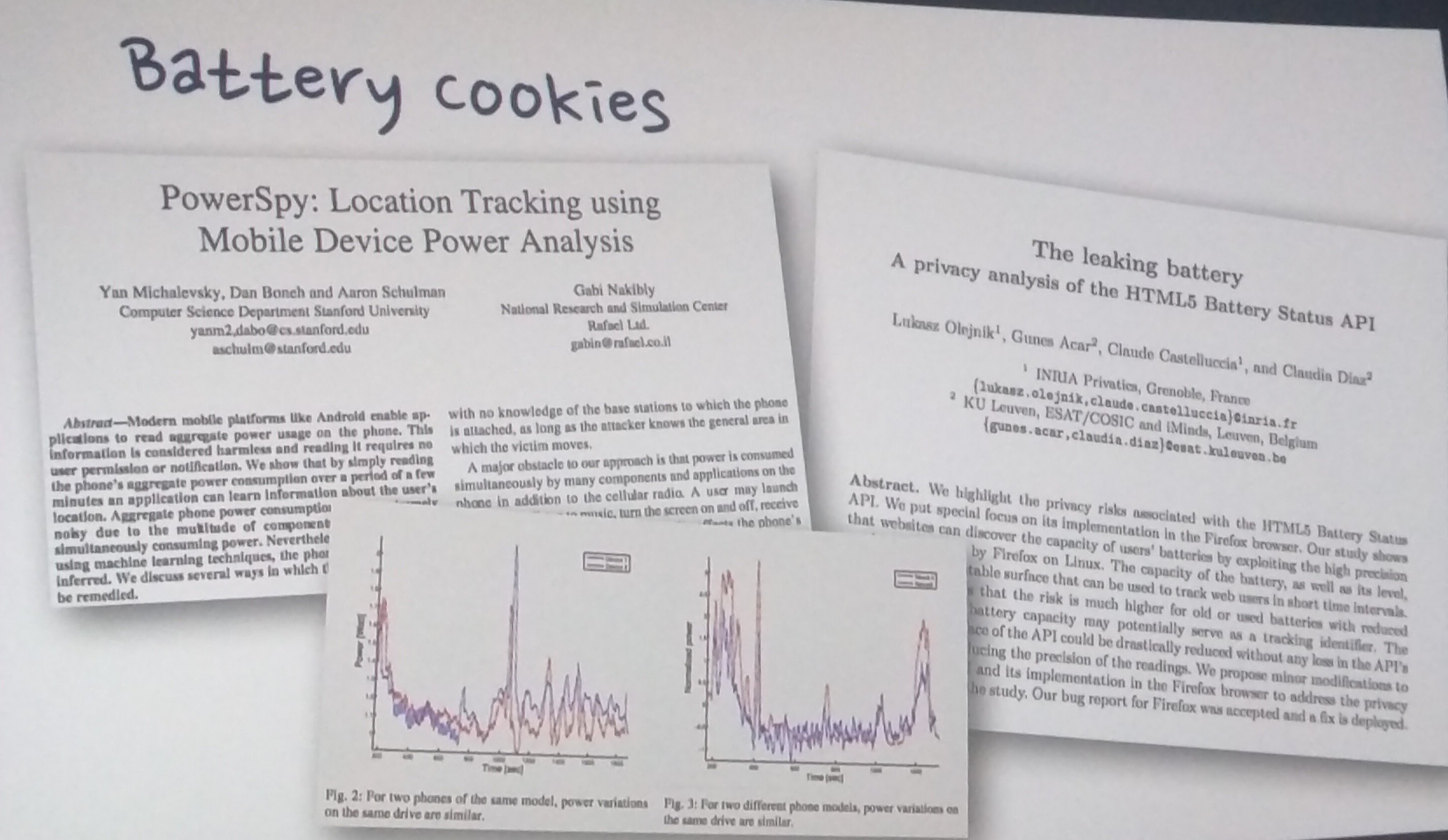 Battery cookies: With this type of ‘hidden’ collection, it is enough to analyze the device’s battery consumption over time to know its location. The strength of the signal varies depending on how far you are from the cellular base. A weaker signal leads to a faster drainage of the battery. This type of apps does not even need to ask for permissions because battery use can be easily accessed as it is considered harmless.
Battery cookies: With this type of ‘hidden’ collection, it is enough to analyze the device’s battery consumption over time to know its location. The strength of the signal varies depending on how far you are from the cellular base. A weaker signal leads to a faster drainage of the battery. This type of apps does not even need to ask for permissions because battery use can be easily accessed as it is considered harmless.
 Trust: The collection of location data might also be considered as a trade-off, but that doesn’t imply that we should blindly agree to the terms and conditions of a ‘free’ application.
Trust: The collection of location data might also be considered as a trade-off, but that doesn’t imply that we should blindly agree to the terms and conditions of a ‘free’ application.
In fact, we should always ask ourselves: Is this app worth giving away my privacy for it? Do I trust what the owners are going to do with my data?
Why Apache Flink Is Better Than Spark (Rubén Casado, Accenture Digital)
As more businesses are migrating from the traditional BI to the big data platform, it is essential to understand the difference between them, illustrated below:
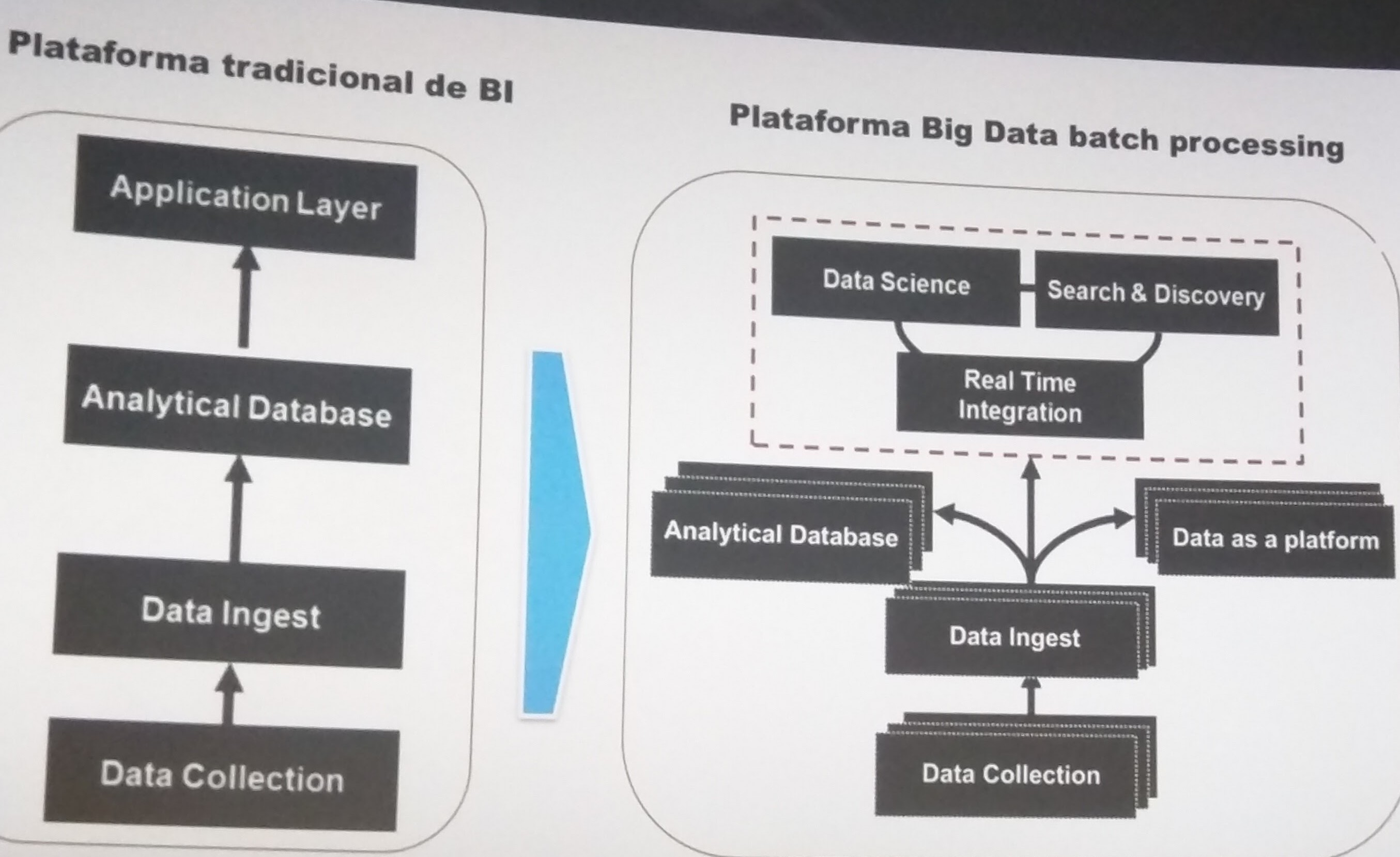
In addition, now that real-time data is proving to be the most valuable when it comes to making timely business decisions, stream processing has come into play. One of its key features is the ability to process streaming data and get real-time insights, which makes it indispensable to ensure velocity in data analysis.
In fact, Stream Processing can be classified into 3 categories: Hard, Soft and Near real-time.
Hard systems (such as pacemakers), with a latency limit of micro or milliseconds, have no tolerance to delays. If delays do happen, they would lead to a system failure and human lives may be at risk.
Soft systems (such as VoIP), with latency up to milliseconds to seconds, have a low tolerance to delay: the system fails but there’s no loss in human lives.
Near real-time systems (usually video-conference), have a high tolerance to delay. There’s no risk of system failure.

There are different types of processing semantics in stream processing systems:
- At-least-once: Every message will be processed at least once. A message may be sent more than once to the application, but we ensure that every message is processed.
- At-most-once: No message is processed more than once, but some messages may not be processed.
- Exactly-once: Every message is processed once. This is the most complex method to implement.
How is processing done in Spark vs Flink?
Spark is based on micro-batches: before it starts processing the data, it needs to divide it into batches, each having a minimum size of 0.5 seconds, which provokes a processing delay. On the other hand, Flink is capable of processing at event time and therefore it does not cause that type of delay.

Keynote by Oscar Méndez, Stratio
In his keynote, Oscar mainly addressed digital transformation and the importance of implementing a data-centric approach to eliminate the need to replicate the data in different places. When our data is at the center of our applications, it becomes much easier to access it in real time. Below is the design and advantages of adopting such an approach.
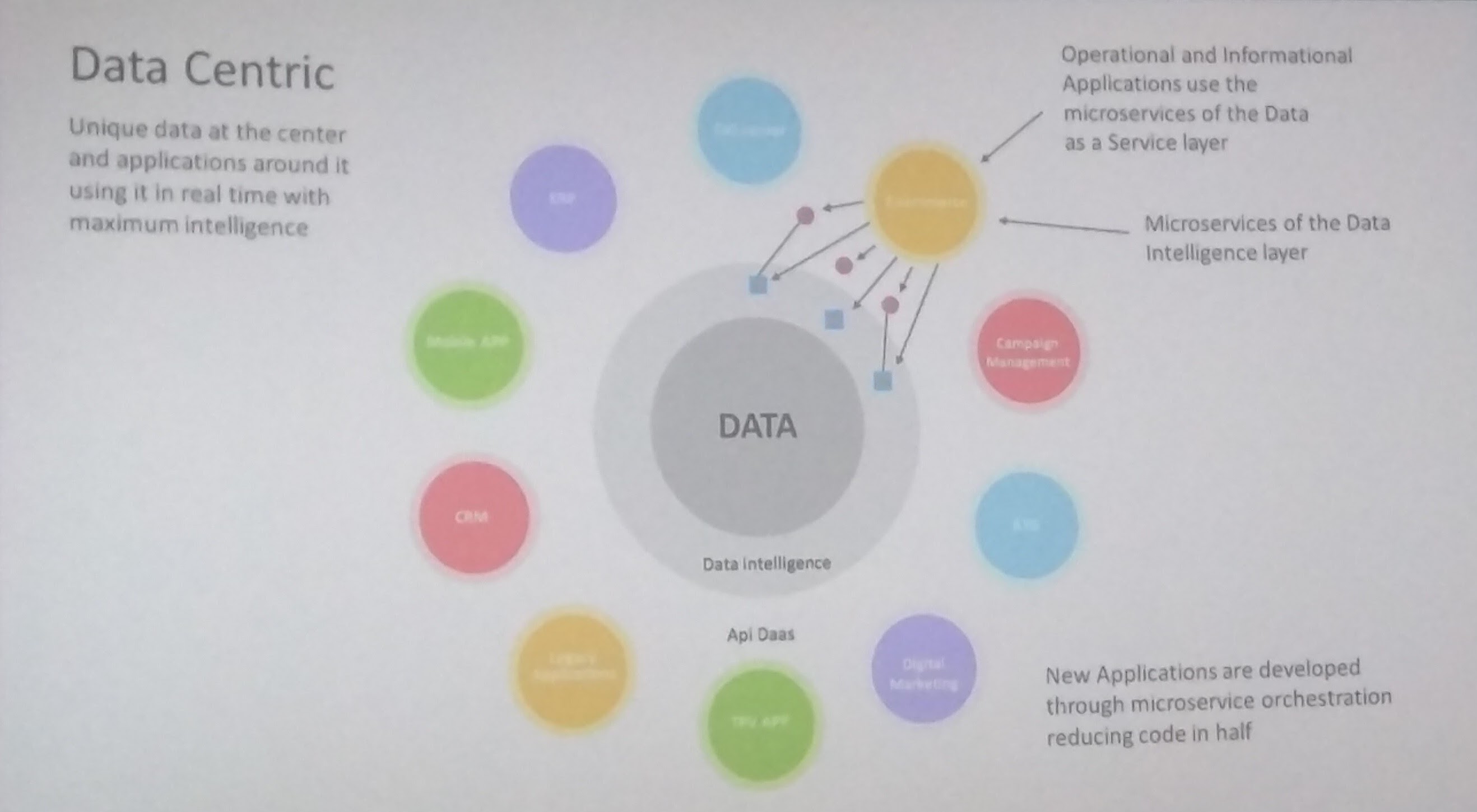

These were some of the ideas I collected from Big Data Spain 2016. Outside of these talks, there were some really cool activities to play with too! MathWorks had their own Enigma crack machine at their booth, so we were able to see how it was decrypting our messages and well, I felt like I was Alan Turing for 10 minutes!
A big thank you goes to the Big Data Spain community for organizing a great event, I hope to make it for next year’s edition!
In the end, what are we again?

***
This post was originally published on 27 November by Sondos Atwi on Linkedin.


