
MLflow, the open-source platform released by Databricks in June 2018, has found a quick and broad acceptance in companies around the world. As stated by Databrick’s co-founder and CTO Matei Zaharia in their presentation post, there were a lot of different tools prior to this, created to track and/or take ML models into production, but they were either proprietary, language-dependent, or able to address only one aspect of the complete Machine Learning lifecycle. MLflow aims to be open in all senses – open source software but also language-agnostic (open interface).
Here at Stratio, MLflow has a prominent role as it is embedded in Stratio Rocket, the evolution of the primitive Stratio Sparta module that enables the design of data processing workflows with little or no code at all, using just a visual tool. In a broad sense, Rocket is an analytical environment that comprises a number of unique features to get the most out of the data you have stored in the Stratio DataCentric platform. From a data-centric perspective, Rocket constitutes the data intelligence layer.
From the very beginning, Stratio Rocket allows automatically deploying a trained model as a microservice. Before MLflow was released, this functionality was restricted to Spark or Scikit-learn models, as Rocket relies on the MLeap library which only supports these two frameworks. Currently, any model that MLflow is able to deploy, can also be deployed with two mouse clicks from Stratio Rocket. This includes models created with a number of popular ML frameworks and libraries, such as Spark ML, Tensorflow, PyTorch, Scikit-Learn, LightGBM, XGBoost, and more. However, not every ML package out there is supported by MLflow, and therefore, some users still cannot see their models deployed and exploited as microservices.
Before going into detail on what it means to support a new framework, let’s briefly review MLflow’s features and benefits.
MLflow key components
MLflow is composed of four main components, each aimed at a different purpose:
-
- <li”>
- : devoted to saving all the configurations tried by a data scientist with different algorithms and the results (performance metrics) obtained. This way, we can later query, review and compare them, always having the results linked with the parameter configuration that generated it. </li”>
-
- <li”>
- : devoted to automatically creating a self-contained environment that includes code, data, libraries (dependencies) and configurations, ready to be shared with other team members. It is a step towards the reproducibility and reusability of data science code. </li”>
-
- <li”>
- : devoted to automatically deploying a trained model as a microservice that can later be queried in a totally language-agnostic manner via API REST. It also supports the deployment of any non-distributed model as a Spark UDF so that we can use Spark to make batch predictions with that model on a large dataset of unlabeled data. </li”>
-
- <li”>
MLflow Model regihttps://github.com/mlflow/mlflow/pull/3304stry
- : this more recent component was added later, and covers the needs for a model repository where the user can track how the model was generated (parameter configuration, data), model versioning and lifecycle. </li”>
MLflow flavors
In order for a model to be easily logged with MLflow or make it deployable (for example, to use MLflow Tracking or MLflow Models with it), there must exist an MLflow flavor which determines how the models created by a concrete ML framework should be saved to disk, loaded into memory again, and queried to get predictions. When an ML framework is not directly supported by MLflow, there’s still an option to implement a custom code using MLflow’s Python function (pyfunc) facility. It is a mechanism to obtain an ad-hoc, fully customized solution in which the user must implement a few functions that are common to any flavor already supported by MLflow.
Despite being valid, this approach requires a deep understanding of MLflow internals, and therefore it is addressed mostly to developers and ML engineers rather than Data Scientists. Ideally, we as users would like to have native support of as many ML frameworks as possible. What if we are using a library that is not supported by MLflow? Instead of just creating an ad-hoc pyfunc and using it in our personal projects, let’s implement the native support by extending MLflow code, and then submit a Pull Request to the MLflow repository so that others can benefit from it in the future! [SPOILER ALERT: check the statsmodels flavor Pull Request]
The statsmodels package
While MLflow already includes many common ML libraries, it lacks a very important one, namely statsmodels. This Python package was created back in 2010 and is one of the few packages that provide statistical modeling capabilities in Python [1]. Differently from scikit-learn, statsmodels emphasizes the probabilistic nature of the models and their statistical properties, not just for prediction tasks. According to the authors, statsmodels can accomplish statistical computations including descriptive statistics, estimation, and inference for statistical models. It covers many classic statistical models such as generalized linear models (including p-values and inference), linear mixed models, additive models, ANOVA, time series analysis, and survival analysis. A complete list of the models available can be found here.
Model serialization with statsmodels: fortunately, statsmodels follows the standard practice of python ML libraries and hence uses Pickle to save/load models to/from disk. This is the same format used by, e.g. Scikit-learn which is already supported by MLflow, which gives us a clue that it should not be very difficult to incorporate statsmodels to MLflow.
How to implement a new MLflow flavor
First of all, we should carefully read this guide and particularly this section. It definitely helps a lot to examine the code of the LightGBM flavor that was added recently. Basically, we need to implement the following functions:
- <li”>def save_model(statsmodels_model, </li”>
path,
conda_env=None,
mlflow_model=None,
remove_data: bool = False,
signature: ModelSignature = None,
input_example: ModelInputExample = None
)
- <li”>def log_model( </li”>
statsmodels_model,
artifact_path,
conda_env=None,
registered_model_name=None,
remove_data: bool = False,
signature: ModelSignature = None,
input_example: ModelInputExample = None,
**kwargs
)
- <li”>def _load_pyfunc(path) # called by mlflow.pyfunc.load_model <li”>def load_model(model_uri) <li”>def autolog() </li”></li”></li”>
Most of the above functions are self-descriptive. We have added the remove_data argument that is fed into the internal call to statsmodels save function, and allows not saving the dataset that was used for training the model, saving a lot of space.
Autolog in MLflow: most often the user will call mlflow.statsmodels.log_param(s) or mlflow.statsmodels.log_metric(s) to log the metrics or parameters he/she needs, many MLflow flavors have an autolog function. The user calls autolog() only once, before starting the execution of the ML code that uses his/her favorite ML library (be it scikit, tensorflow, etc). The user code remains unchanged, with no references to MLflow except for the call to mlflow.<flavor_name>.autolog() at the beginning. Under the hood, every call to the ML library causes MLflow to automatically log a few parameters and/or metrics, in a way that is totally transparent to the user.
Implementing function mlflow.statsmodels.autolog is a bit more complicated than other frameworks. In this first version of the statsmodels flavor, we only support method fit of a statsmodels algorithm. It will cause MLflow to log the fit arguments and the results, including fitted model parameters and performance metrics, with an emphasis on p-values and statistical properties of the fitted model. We only autolog those parameters that are either one-dimensional (real numbers or strings), or n-dimensional vectors with n = number of features in the data.
Monkey patching

In Python and other languages, monkey patching is a technique that consists in replacing existing methods or functions by other ones at runtime. It helps in implementing autolog as it allows replacing the native statsmodels functions (in our case, only the fit function) by our own function which will log model parameters and metrics before and after calling the original statsmodels fit function. Inspired by the LightGBM flavor code, we have used the gorilla python package for this, carefully ensuring that our function keeps a link to the original statsmodels fit function.
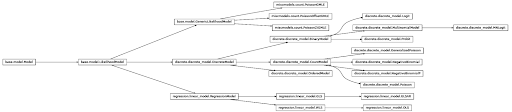
Figure 1: the statsmodels class hierarchy (showing models classes only)
Here comes the tricky part: when we examined the class hierarchy (Fig. 1) of the statsmodels package, we realized that many algorithms override the fit function, and furthermore, an overridden fit function often calls the superclass fit at some point of its own implementation, but within the context of the subclass. For this reason, keeping the right link to the original function was a bit more complicated and could not be fully accomplished with the gorilla package, so we had to design a different mechanism:
def wrapper_fit(original_method): # function object with the original fit func
def fit(self, *args, **kwargs):
# Do stuff. Check if this is the outermost call
model = original_method(self, args, kwargs) # call original fit
# More stuff: if this is the outermost call, log params and metrics
return model
return fit
Moreover, since there are many different fit functions inside statsmodels, we had to monkey-patch (i.e. replace) all of them, which required recursively traversing the whole statsmodels class hierarchy, examining each class to check whether it overrides fit or not, and if it does, replacing it with our own fit function:
subclasses = set(find_subclasses_recursive(statsmodels.base.model.Model))
# Create a patch for every method that needs to be patched: those
# which actually override an autologgable method
# Link the patched function with the original via a local variable
# in the closure to allow invoking superclass methods in the context
# of the subclass, and not losing the trace of the original method
patches_list = [
gorilla.Patch(c, “fit”,
wrapper_fit(getattr(c, “fit”)), settings=glob_settings)
for c in subclasses if overrides(c, “fit”)
]
# Finally, apply all patches
for p in patches_list:
apply_gorilla_patch(p) # a customized apply patch function
Our fit implementation just creates a new MLflow run if there’s none running, logs the arguments, calls the original function and logs the results when it returns. IMPORTANT: no matter how many internal calls are done to other classes’ fit method, the only call that should log the results is the most external one, i.e. the fit method that was called directly by the user. We account for this through a class variable (a shared boolean flag) that is set by the first call to fit (i.e. the most external, invoked by the user). This flag prevents any other recursive (internal) call to the patched fit from also logging stuff since it will find the flag already set.
Of course, at the same time, we develop our code, we must develop enough test cases to cover all the new functionality. The test cases were heavily inspired by those of the LightGBM Pull Request, including a number of different statsmodels models to ensure they can be saved and loaded, logged, and also auto-logged. Keep in mind that some statsmodels models do not have a predict method (although most do have) and some others are not pickable.
Summary
MLflow is a very nice open-source framework that solves the most common needs related to ML model’s lifecycle, covering code sharing, experiment tracking, model deployment, and lifecycle management. It is compatible with many popular ML frameworks and libraries, but still lacks integration with the statsmodels package. We deem this integration necessary as statsmodels is among the few Python packages that perform statistical modeling and inference. We have described how the integration can be accomplished as a new flavor for MLflow. We hope the Pull Request will eventually be accepted and merged so that we can benefit from it in the next MLflow release. Fingers crossed!
References
[1] Seabold, S. and Perktold, J. (2010) Statsmodels: Econometric and Statistical Modeling with Python. Proc. of the 9th Python in Science Conference (SCIPY), 92 – 96.


