
Over the last few years, the volume of data that is generated daily has grown exponentially, sources of information are getting more heterogeneous and data has all kinds of formats, both structured and unstructured. In this sense, the irruption of Big Data has caused a great technological revolution, which has allowed us to exploit all these types of information and to do it in real time, something that was totally unimaginable until this moment (I expect I have not told you anything new so far!).
In this context, data has become for many companies their most important asset. Ensuring quality of the information, as well as carrying out a proper management and governance of the data, is absolutely essential.
In this post we will discuss different aspects related to data quality in a data-centric platform.
Work methodology and typology of controls
Generally, governance in terms of data quality includes the following parts:
- Execution of the control model
- Generation of quality metrics
- Definition and implementation of action plans to improve data quality
- Reporting and monitoring of the evolution of quality
Work methodology for carrying out the controls is usually performed as follows:

There are different types of controls such as:

What changes in terms of data quality in a data-centric platform?
Greater importance of control models
The existence of a complete and reliable control model is always critical, in order to ensure consistency, accuracy, completeness, validity and availability of the data throughout the end-to-end process (ingestion, preparation and enrichment of the data, modelling, etc.).
However, this is especially relevant in these type of environments, where data-flows are sometimes performed in streaming and information comes from completely different data stores with completely different formats.
The main risks of not having an adequate control model are the following:
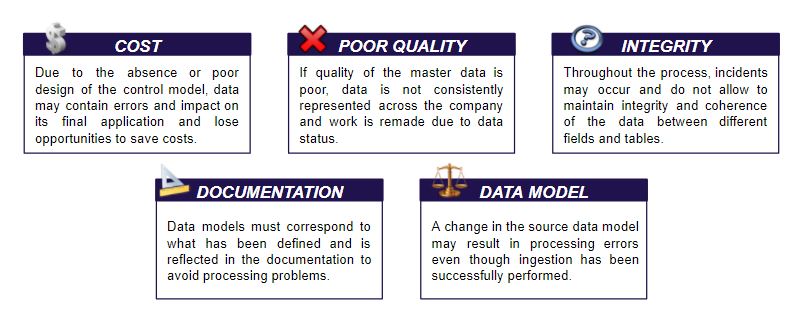
In order to avoid these risks, it is necessary that the control model is specifically defined for each solution, depending on its architecture, processing and typology of data that needs to be validated.
Greater control without duplicated processes
A data-centric model such as Stratio DataCentric allows you to centrally store all information in a single repository, building a unified view of the customer from the business point of view and regardless of the source the data comes from.
All information ingested into a data-centric platform must be governed, under control and with adequate security and data quality policies. Having all data centralized allows you to have greater control as there is only a single point of access to the platform’s information (this does not mean that the data is unique or that there is only one way to access the data). Additionally, all processes carried out in relation to data preparation or quality improvement are performed in a data-centric platform without duplicating processes and work in different applications (not application-centric).
New typologies and sources of data
As can be seen in the image, what is actually known and controlled in conventional environments makes up a very small piece within the whole Big Data ecosystem. It is only related to structured internal information. In this case, controls are often already implemented in the entity itself with typical validations such as:
- Completeness
- Integrity
- Duplicity
- Format
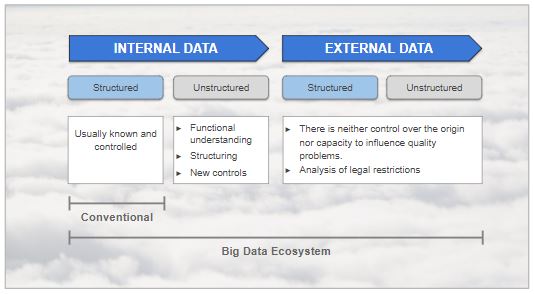
Regarding unstructured internal data, the following aspects must be taken into account:
- A detailed functional understanding of the information is required, in order to be able to structure the information and define new controls.
- In many cases (e.g.: technical logs) the quality of the data is very poor and there is a large number of duplicates, completely null records, etc., so the controls that identify these casuistics need to be executed.
Finally, in relation to external data, regardless of whether they are structured or unstructured, there is neither control over the origin nor capacity to influence quality if an error is detected. Because of this, potential problems need to be identified as soon as possible and fixed within Stratio DataCentric before they are exploited.
Validations in unstructured data
Here are some examples of controls that can be implemented in relation to unstructured data, but they need to be adapted case by case to the type of data that will be validated:
- In unstructured data, the most important thing is to structure the information and execute controls on them afterwards (for example, expiry date of electronic IDs to verify that they are not expired).
- You need to validate that no information is lost in the structuring of the data. Generally, this is controlled through a final field that collects any data that has not been taken into account.
- Parsing of fields may require the use of complex regular expressions and, for this reason, it is very important to verify that resulting fields have coherent values and expected length.
- Validations on semi-structured data also need to be performed (for example, completeness and format controls in .xml files).
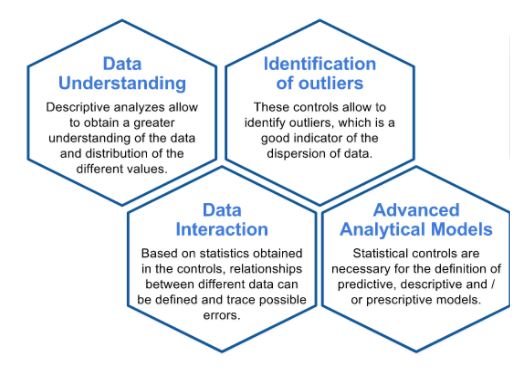
Statistical controls
Statistical controls allow you not only to perform an analysis of the quality of the data, but also provide other mathematical measures such as mean, median, percentiles, etc. This allows you to obtain greater understanding of the data and identify if there are outliers and dispersion of data, which are key aspects for the design of advanced analytical models.
Convinced of the importance of data quality controls?
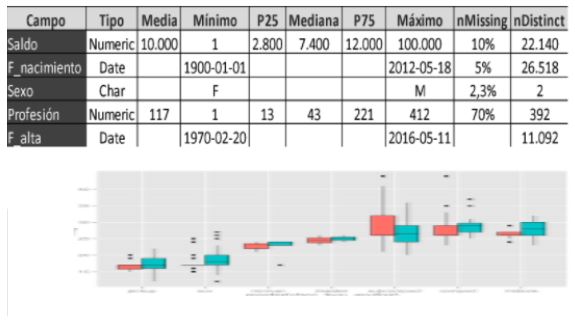
In case there is still some skepticism, I will give you a real example from just a couple of weeks ago. One of our clients was about to develop an advanced analytical model and we implemented a control to verify that there were no relevant variations in the volumetry of the “Accounts” and “Statements” tables from one month to the other. We obtained the following result:
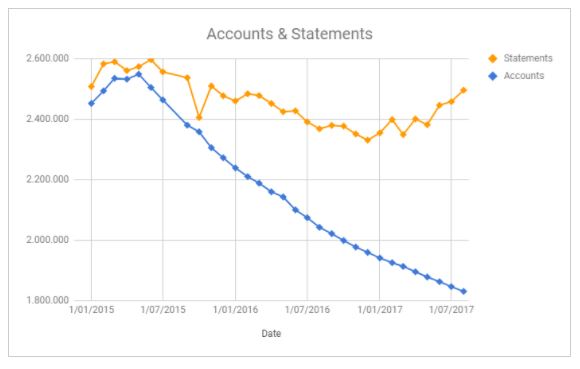
As you can see, the monthly volume of the “Accounts” table was decreasing over time, even though the “Statements” table did not have this evolution, so that everything indicated that there was a problem in the data.
The client reviewed the results and confirmed that an error existed: a new extraction of the data was required. The new result of the control was as follows (now the evolution of both datasets makes sense):
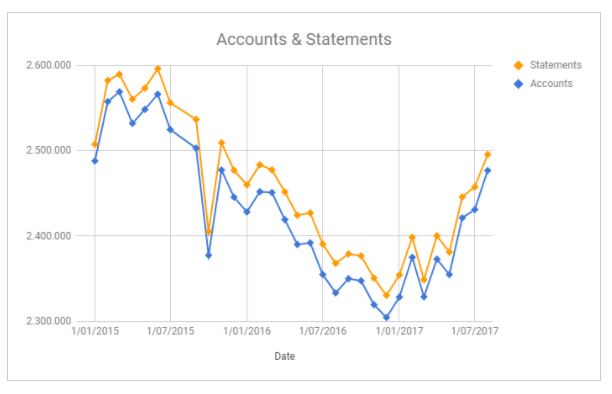
If we had not carried out the controls, the data used for the analytical model would have been incorrect and, therefore, the conclusions obtained as well. A wrong conclusion can lead, for example, to unnecessary costs, inefficiency at any given time or losing an important opportunity.
I hope that there is no doubt left about the importance of having adequate data quality controls. The question now is: how do I do this in our data-centric solution? We will tell you in an upcoming post… 🙂
“Quality is never an accident. It is always the result of intelligent effort.”
John Ruskin


